The one characater performance fix
Note: This writeup is based on a production issue that I encountered for a vendor app. I used what I learned from the experience to write up an independent demo to show the potential impact this problem can have on a production system.
We’re going to demonstrate the impact of parameter data types on performance. For this scenario we will create a 1 table database that contains user sessions. During typical use, we’d have 1 row per active session in this table and inactive sessions are cleared on a schedule. We will use a session_cookie column to store the unique cookie that identifies a session, then on every time we need to check if a session is valid, we will use a query to check for this. The code below creates a table and simulates 50,000 active sessions.
DROP TABLE IF EXISTS dbo.sessions
CREATE TABLE dbo.sessions(
id BIGINT IDENTITY(1,1) NOT NULL,
session_cookie VARCHAR(32) NULL,
ts DATETIME NULL
INDEX IX1(session_cookie)
)
DECLARE @i int = 0
SET NOCOUNT ON
WHILE @i < 50000 BEGIN
SELECT @i = @i + 1
INSERT INTO [dbo].[sessions] (ts, session_cookie)
VALUES (GETDATE(), REPLACE(CAST(NEWID() AS VARCHAR(64)), '-','')
)
END
In our scenario, our application uses a parameterized query (likely product of an ORM) to check for sessions as below:
DECLARE @p1 NVARCHAR(4000) = 'mycookievalue'
SELECT id, ts FROM sessions WHERE ( session_cookie = @p1 )
At a first glance, you may think this is a pretty OK query given the parameterization as well as the existence of an index on the session_cookie column we are filtering for. But when we look at the execution plan, it’s quite disappointing (400 logical reads):
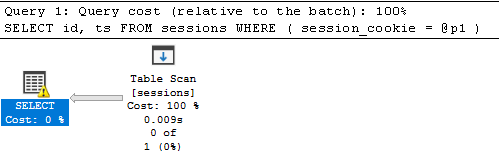
The little exclamation point is trying to tell us why this is happening, specifically Type conversion in expression CONVERT_IMPLICIT(nvarchar(32),[sample].[dbo].[sessions].[session_cookie],0)=[@p1] may affect "seek plan" in query plan choice. What this is telling us is, the data type of our column is VARCHAR but the parameter we’re passing is a NVARCHAR and SQL Server is not able to use the index that’s in place and is instead casting every value in the column while scanning the entire table to see if there is a match. Now let’s take this advice and fix our query by removing the extra “N”:
DECLARE @p1 VARCHAR(4000) = 'mycookievalue'
SELECT id, ts FROM sessions WHERE ( session_cookie = @p1 )
And we’re now getting a much better plan (3 logical reads):
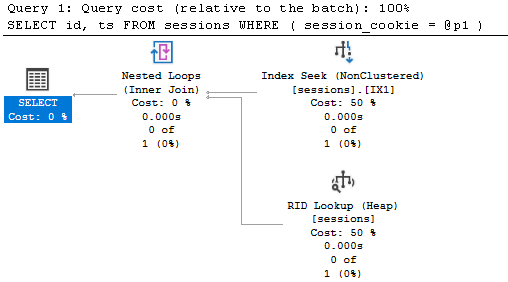
To put this in perspective - in our case this was the difference between 100% CPU vs 10% CPU on an otherwise quite busy system (storing sessions is a minor functionality for this application). Let’s demonstrate that with a quick Python script:
import pyodbc
import concurrent.futures
import time
def run_query(cnt):
query = """ DECLARE @p1 NVARCHAR(4000) = 'mycookievalue'
SELECT id FROM sessions WHERE ( session_cookie = @p1 ) """
connection_string = 'Driver={ODBC Driver 17 for SQL Server};Server=tcp:myserver,1433;Database=sample;Uid=myuser;Pwd=mypw'
conn = pyodbc.connect(connection_string)
cursor = conn.cursor()
start_time = time.time()
for i in range(cnt):
cursor.execute(query)
conn.close()
return time.time() - start_time
if __name__ == "__main__":
thread_count = 25
run_count = 500
with concurrent.futures.ThreadPoolExecutor(max_workers=thread_count) as executor:
futures = [executor.submit(run_query, run_count)
for _ in range(thread_count)]
results = [f.result() for f in futures]
runtime = sum(results)
print(
f"Completed {thread_count} threads with {run_count} queries each, total time: {runtime:.4f}s")
This script creates 25 threads to run this query 500 times each. This is not an unrealistic scenario, if anything in a real world scenario there would be more concurrent requests as every page load in this application needs this data. Running this test with the original code on a respectable 8 core server doing nothing else yields this:
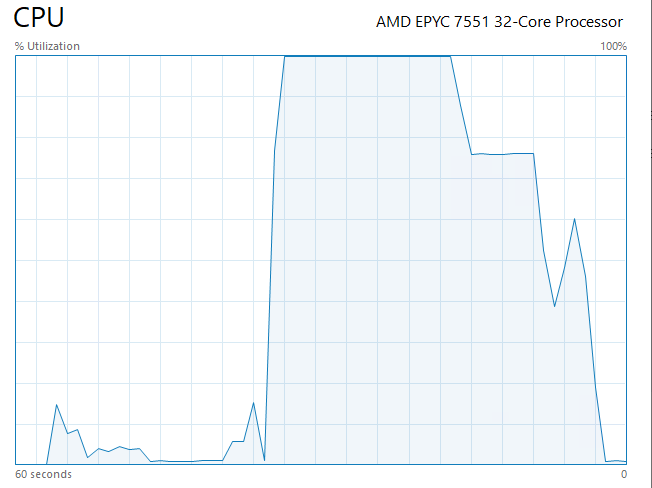
> python .\sqltest.py
Completed 25 threads with 500 queries each, total time: 678.3122s
When we report this issue, the vendors knee-jerk response is usually that we need to rebuild our indexes (failing to acknowledge that this is indeed a design flaw) So let’s do that to demonstrate how that changes things.
ALTER INDEX ALL ON sessions REBUILD
EXEC sp_updatestats
And now we get
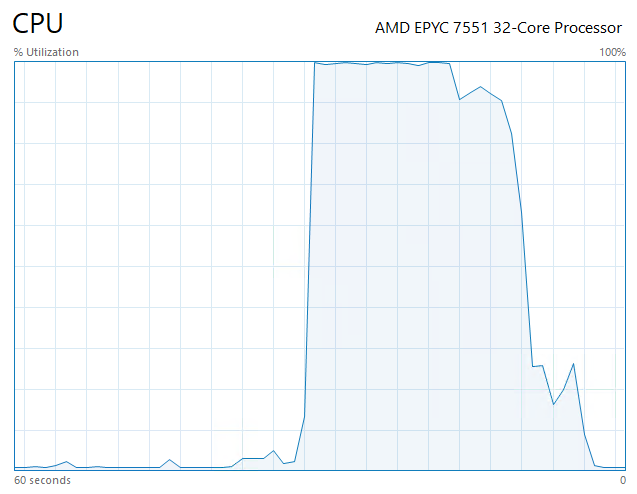
> python .\sqltest.py
Completed 25 threads with 500 queries each, total time: 521.9987s
There is definitely some improvement (confirmed over multiple runs) if we rebuild the index after the inserts. But we’re still pegging the CPU with 25 threads. Now let’s apply our one character fix by running the same Python script but replacing NVARCHAR(4000) with VARCHAR(4000) to see what this gives us. (The database was rebuilt for this run, without doing any index rebuilds - so same setup as test 1)
> python .\sqltest.py
Completed 25 threads with 500 queries each, total time: 47.4932s
This is a great example on how important it is to use correct data types for parameters - especially in frequently executed critical queries. I’ve run into this situation in other scenarios where tables where created using VARCHAR columns and the ORM (Spring/Boot for example) default to NVARCHAR since the strings in the language are Unicode by default. In this case it may be best to use NVARCHAR in SQL - especially if you can get Unicode input but a quick fix can be to tell your driver that your strings in SQL Server are not Unicode by using a connection string parameter like sendStringParametersAsUnicode=false for jTDS. This is only a good idea if you don’t use NVARCHAR at all and is a quick fix/workaround, documentation for jTDS can be found here